如何克服AB测试中的赢者诅咒【UXRen译#205】

作者:Milan Shen(Statistician, Data Scientist@Airbnb) | 翻译:Ivan 审校:dodo
前言
我们通常选择A/B测试中表现出显著优势的方案进行发布。如果我们的连续做很多次测试,然后找到了一些表现出显著效果的方案,那么如何评估这些方案的综合效果呢?直接把所有方案的测试结果相加吗?
在这篇文章中,Airbnb的数据科学家Milan Shen研究在评估被选方案的综合影响时直接加和的方法可能会产生的选择偏差( 赢者诅咒),并提供了如何修正偏差以得到综合效果的无偏估计。 (注:在下文中,A/B测试也被称为 “实验”)。
什么是选择偏差?
作为在一年多前才进入数据科学领域工作的统计学者,我(Milan Shen)很开心能够看到大家都在应用实验的方法来指导产品和商业决策。统计推断和假设验证构成了我们这些“数据分析师”的日常工作,对随机性的深度认知指引着我们的决策。然而,这个充斥着大数据和大范围A/B测试的时代无疑给我们旧有的方法论带来了新的挑战。
如果你在大型的A/B测试平台进行过实验探索,那么你可能有过这样的经历:数据无法自洽。举个例子:Airbnb曾经在几个月内连续进行了多次A/B测试,得到了6个表现出显著性差异的实验结果,然后我们就向全部的用户(小部分用于Holdout验证的用户除外)发布这6个产品方案。在实验成功刺激下,我们试着将这些方案的影响效果加和统计起来,然后发现加和的结果与Holdout验证组的结果有一定的差距,如下图:
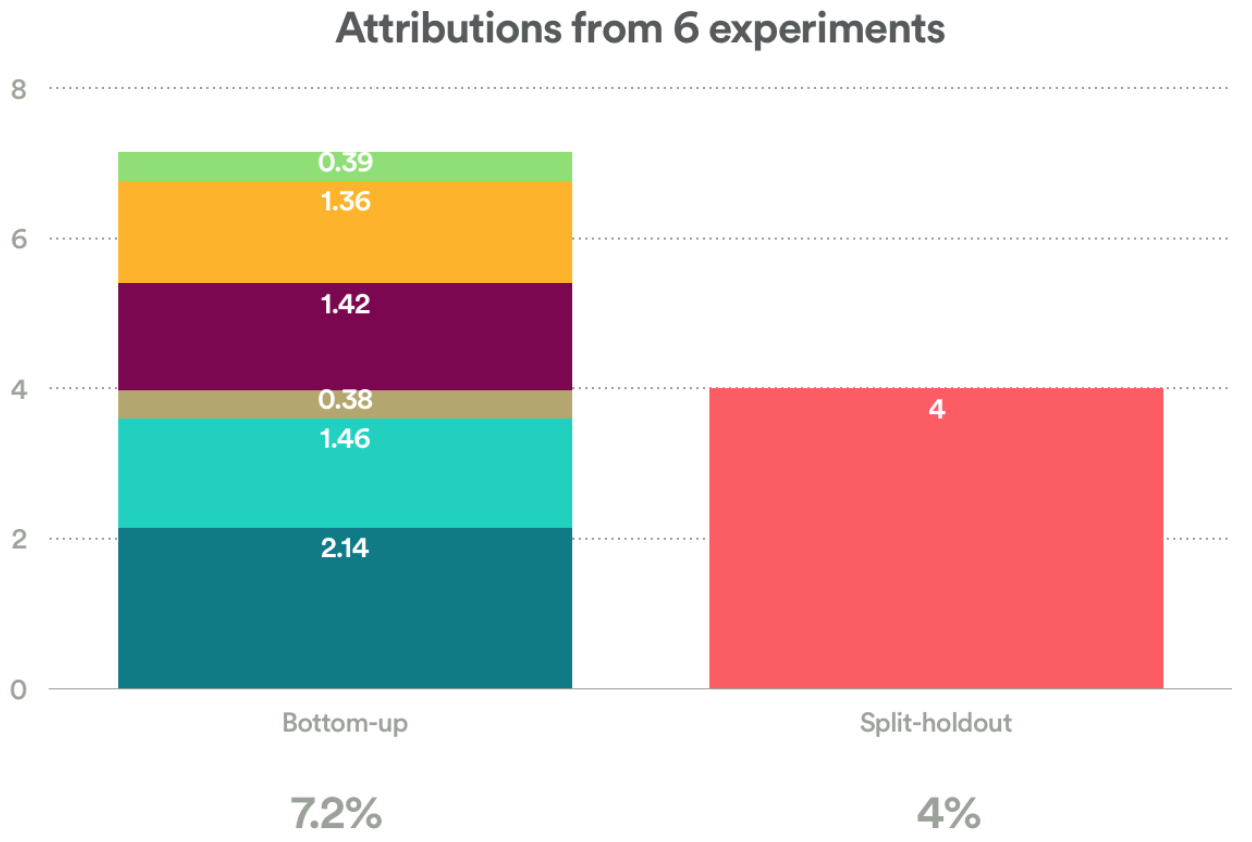
在自下而上估算(bottoms-up calculation,图左)中的每个数据是每次实验中测验指标的增量,而图右则是实验方案在验证组中的指标表现。前者的求和与和后者均是对于产品方案的综合效果的测量,但在绝对值上前者的总和明显超出了后者。我们该怎么解释两种方法得出的数据差异呢?
你的第一个想法可能是“等等,每次实验的增量可以直接求和的吗?”
我们这么做当然是有理由的:
- a)这些实验是一个接一个的连续进行的;
- b)如果我们假设每次改变所带来的百分比提升都是很小的,那么用加法或者乘法都能计算其累积效应(即当x很小时的log(1+x)~x )。
但同样,换个角度来看这样做也是有问题的。即使没有足够的专业知识我们也能够想到自下而上估算具有诸多的潜在风险:
- 测试结果的方差不同
所以每次实验结果的置信区间也是不同的;因此7.2% 和 4%之间的绝对差异并不具备统计显著性。 - A/B测试受到淡旺季影响
Airbnb所在的旅游行业是避不开的,所以尽管影响测试多次连续性的测试,测试结果也可能受到了时间线影响的。 - 短期效应VS.长期效应
有的时候单独的A/B测试只在短期内表现出正向的效果。将这些短期效应直接加和并不能用于评估产品的改变在对照组中的长期效应。 - 实验组和对照组的相互侵蚀
即使每场测试的结果的无偏的,不同组别间用户的交互可能导致样本量比例的变化,并进而影响测试效果。Airbnb将这种情况称为侵蚀(cannibalization),在本篇文章中不会过多提及。
以上的任何一点展开来讲都够一篇单独的文章了。但是,这些因素导致的计算失误我们还是可以原谅的,我们在这里希望探索的是另一个更加普遍的影响因素,几乎在所有线上实验平台中我们都能可能看到它:选择偏差(也被称为赢者诅咒(selection bias, aka. Winner’s Curse))
你是否受到赢者诅咒的困扰?
赢者诅咒原意为在竞价拍卖的交易中赢家虽然最终购得竞拍品,但却因为层层加码而付出了超出收益的成本的现象。
在这里我们用来类比:通过显著性选择出来的一些实验结果对真实效果的估计往往会比真实效果要高的现象(挑选出了优胜者但实际得到了不准确的评估)。来简单解释一下为什么:
假设我们进行10次A/B测试,每一次测试的标准差都是1%。我们在每次测试中都有足够的样本参与,然后得到每次测试效果如下图中的第一行数据。同时,图中的第二行数据代表了真实效果,但我们暂时假装并不知道它们。

我们通过t检验来检测每次测试的结果。如果采用按照显著性水平α = 0.05来计算,在这个例子中t值就等于观测值,所以测试结果需要大于1.96才能说明统计学的显著。因此,我们可以有3次显著的测试结果,如下图的红框标注:

因此,如果我们把三次显著的实验结果相加可以得到:2.7% + 2.6% + 3.3% = 8.6%。但是,其实我们是知道真实效果的,而它其实只有1% + 1% + 4% = 6%。这就构成了2.6%的偏差。
好吧…我们承认了以上是一个不怎样的案例展示,我们能够借助一些简单的假设来把这些偏差用数学公式表示出来:假如X1, …, Xn 是某个概率区间内的随机数值,且 Xᵢ的均值为aᵢ 、方差为σᵢ²。那么aᵢ 就是我们所不知道的真实效果,而在实际操作中我们通常使用无偏差的Xᵢ 来估测aᵢ的值。
再回到日常的A/B测试中,我们通过独立样本t检验来检测每次测试结果,并且选择那些结果“显著”高于阈限值的产品方案去发布。假如我们在每次测试i中使用的显著性水平是αᵢ 。而我们先暂时假设σᵢ² 是已知的。我们选出来的产品方案就符合公式:Xᵢ /σᵢ> bᵢ, bᵢ 显著性水平αᵢ参考分布的阈限值,通常为0.05。
如果我们把入选方案用集合表示为 A= {i|Xᵢ /σᵢ > bᵢ},那么对这些方案的真实效果求和就得到:T_A = ∑{i ∈ A} aᵢ。而如果我们把每次测试的观测结果求和就得到:S_A= ∑{i ∈ A} Xᵢ .注意,因为A是个随机的数列,所以T_A也是随机的,且基本上ES_A ≠ ET_A。同时,将预期的真实效果值用公式表示就是:E[T_A] = E[∑{i ∈ A} aᵢ].
事实上,如果我们能够证明ES_A ≥ ET_A,如下图:
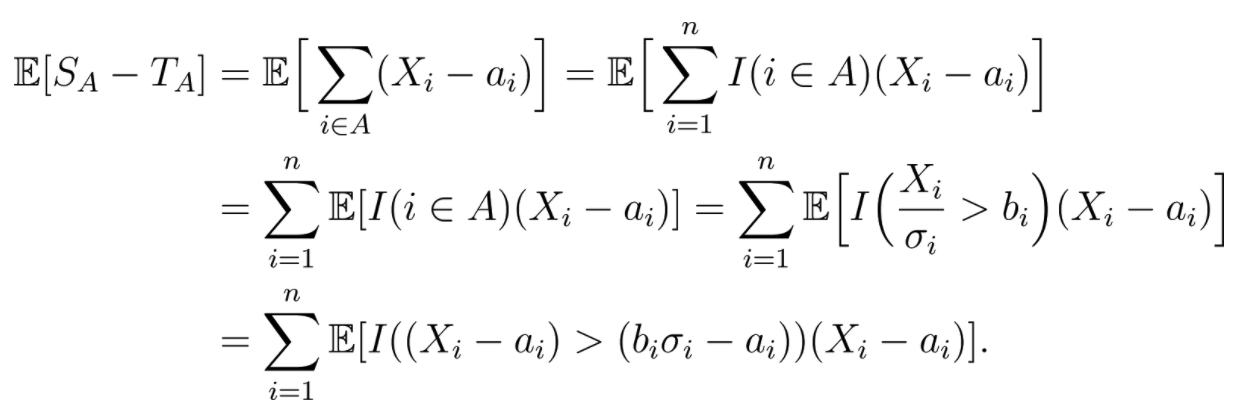
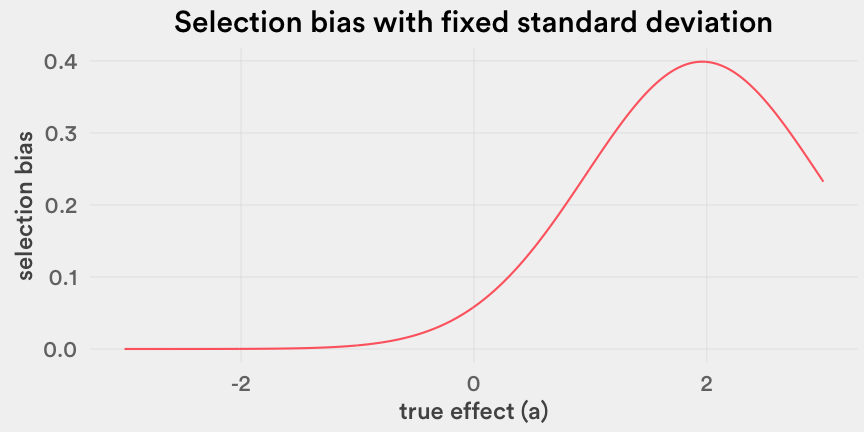
考虑到在均值为0的分布中低截断部分的均值总是一个正值,则这些均值的所有加和项也是正值,进而可以判断“选择偏差”也基本是一个正值。看看在下面的图中,我们将以上求和公式构画成出来就获得了真实效果 aᵢ在正态分布情况下的函数(当然,别忘了我们的假设σᵢ =1,bᵢ是t检验中两个标准偏差的阈限值,即1.96 )。
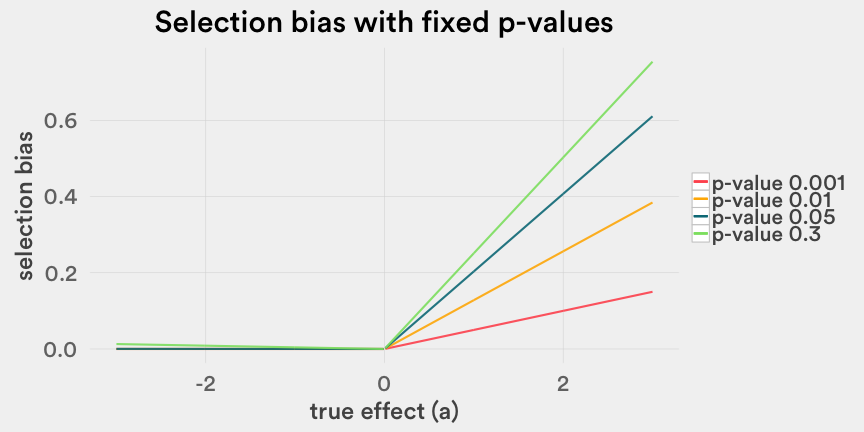
然后,我们还能构画一个描述效果和p值的图表来描述选择偏差。如下图,可以看到偏差量也随着真实效果的增加呈现出线性增长的趋势。
现在,我们就清楚了:如果我们能够获得加和中每个数据的无偏估计,那么我们就能够对选择偏差(E[S_A -T_A])进行量化.
赢者诅咒发生在“选择”的过程中,即在我们每次挑选A/B测试中的优胜方案并试图通过将它们各自的效果求和用于估计整体效果的时候。
我们当然知道一次恰当的数据模拟比以上这几千字会更具说服力,所以请看看下面的图:我们通过数据模拟来展示自下而上估算的结果确实是比真实效果(X轴)显著要高的。假设我们进行了n=30次A/B测试,并记录了优势方案对目标数据的提升效果。对每次测试i,我们从截尾正态分布中取样了 Zᵢ ~ N(0.2, 0.7²)时的 aᵢ ~ Zᵢ|(-1.5 < Zᵢ < 2),和形状参数为3、尺度参数为1的逆伽马分布中取样了σᵢ² 。为了在数据模拟中获得更多正向的真实效果(在产品以提升数据指标为目标的情景下有理有据的假设),我们预测真实效果的分布是一个左偏态分布。在1000次数据模拟中,几乎每次模拟都表明自下而上估算的结果都在真实效果的45度对角线之上。
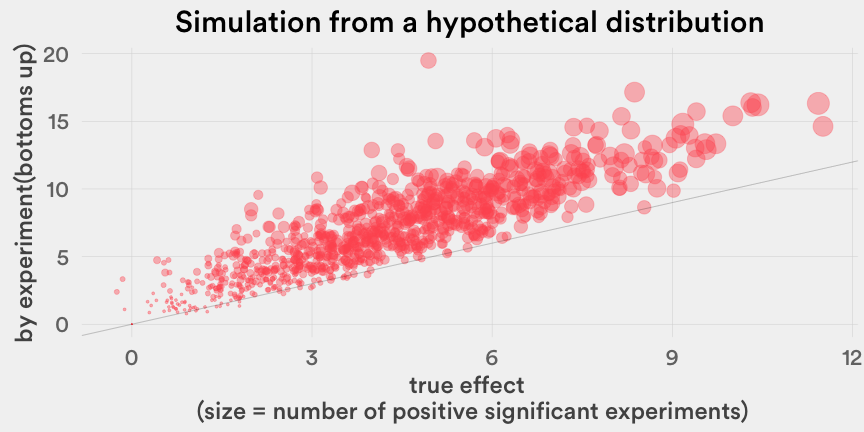
选择偏差真的…是个问题吗?
如果你听说过“多重检验”的话,那么这些内容可能对你而言已经很熟悉了。确实,我们做的事情就是在测试多重假设,而且采用了一些巧妙的调整来控制拒真错误或多重比较谬误。Bonferroni校正、Benjamini-Hochberg的FDR校正法等方法也能够用于解决这些问题。如果在测试中使用统一的显著水平值,我们会更容易获得一些显著性的方案,即使这些结果可能都只是没什么意义的噪音。
但是,在这篇文章里我们试图解释的可不仅仅是误报率。对于选择偏差而言,我们希望能够明晰的问题有两个:
- 首先,即使在误报率为0的情况下(例如我们所有的A/B测试结果都是准确的),单纯的加和每次测试的效果仍然是对实际效果的高估;
- 其次,那些没有被选择(结果不显著)的测试,也为偏差的产生做出了贡献。
对于某一个单独的我们得到的优选方案而言,其A/B测试的观测效果也很有可能是超出了真实效果的。通常我们将样本的均值视作总体样本均值的无偏估计。然而,因为我们通常只在发现某次测试表现出显著结果以后,开始对其保持异常的关注。我们所得到的观测效果事实上是在某个方案已经表现出了效果或者是观测值超过某个阈限之后的值了,这一过程无疑导致了向上偏误的产生。
其次,从上述的公式中我们也看到即使是那些并不显著的A/B测试也在为选择偏差添砖加瓦,这听起来是有些不可思议。为什么我们对估测ET_A的值尤其感兴趣?如果我们只关注那些表现出显著性差异的测试,那么我们能够修正T_A|A;然而,我们并没有这样做,我们把所有显著和不显著的测试均纳入了计算中。这是完全不同的做法,但是我们认为这样更能够反应真实的测试过程。让我们来举例说明一下:
- 情景1:某人进行1次A/B测试,得到了显著性的结果,计算得到的实验效果X₁= 1且p值小于0.001;
- 情景2:某人进行1000次A/B测试,其中一次表现出了显著结果,并且其实验效果X₁= 1且p值小于0.001;
直观来看,如果我们在两个情景中采用同样的方式计算总体效果,那么因为选择偏差无疑存在着高估情景2真实效果的风险。使用ET_A 来修正最后的结果会将这种风险考虑进去。另外,如果考虑只有第一次试验结果是显著的情形,那么修正结果对情景1和2而言则是相同的。
所以如果我们在试验一开始就计划好需要参与加和的实验数量A,那么就不会产生选择偏差了。最终,偏差存在的原因还是因为我们在众多A/B测试中挑选了试验成功的那部分,而且在大型测试平台中我们需要经常这样做。
所以…我们能做些什么?
如果你的工作内容包括向其他人宣布A/B测试最后产生怎样的成果,那么这个你就需要为这一选择偏差负责,或者通过更好的实验设计努力避免偏差了。
从上面的公式中我们能够很直接的得到赢者诅咒的无偏估计方法。假设真实变量 aᵢ 和 σᵢ² 都是已知的,那么我们就能推导出偏差E[S_A -T_A]的公式如下:
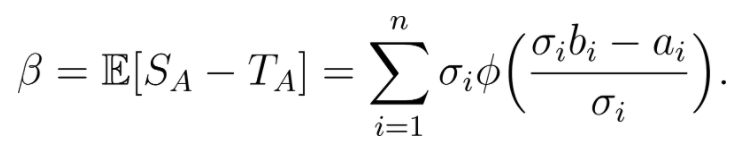
但考虑到aᵢ 和 σᵢ² 都是通常是未知的,我们使用测量值Xᵢ 和 W ᵢ(Xᵢ 的标准差)来代替它们来得到选择偏差的估测值:
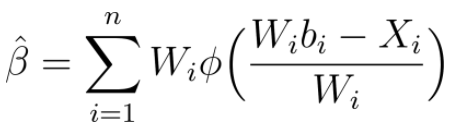
从自下而上估算法的结果中减掉选择偏差就是对真实效果的无偏估计了。Airbnb的ERF平台(Experimentations Reporting Framework)新上线了一个功能来自动计算这个偏差。通过ERF还能够选择出部分显著的测试出来,指定需要分析的数据指标和分析规则。同样也能够通过自主抽样法来计算无偏估计的置信区间。例如,对之前的示例数据进行无偏估计得到的综合效果为5.3%而不是7.2%,同样的我们也能够看到这个效果的置信区间是比较大的。
这个去除偏差的方式依赖于极少数的假设条件,尤其是与需要很多专业知识的Bayesian等方法对比而言。在构建这个方法并将它应用到ERF的过程中我们也学到了一些事情:
- 在选择的过程中要尤其谨慎并且做好团队沟通。
就像示例中所展示的那样,偏差是正向的所以去除偏差以后的效果值会比自下而上估算的值要小一些。尤其是,我们进行越多的实验且实验结果都很理想的话,就越容易在自下而上估算中产生偏差。当每次实验都包含有团队的努力付出时,要做到客观看待并接受高估的存在并不容易。 - 在实验开始之前就确定好假设和发布条件,然后再应用偏差修正的方法。
如果没有收据额外的数据,试错法通常会带来不准确的测量。我们希望能够在注重速度的时候同时保证实验的质量。为了应用偏差修正的方法,我们希望能够有一个简单的选择原则,比如每次实验的阈限值为 bᵢ 。需要注意的是,我们必须在没有接触到实验数据之前就把这些阈限值确定下来。因此在实验开始之前就有明确的假设和发布条件就很关键了。 - 谨慎选择要预估哪些实验的效果。
选择的数据系列{1,…, n}决定了偏差的来源,因此在事前进行恰当的选择是很重要的。这些选择的意义重大且选择过程的开始取决于我们自己的判断。从经验来看,我们应该选择那些某段时间内某个团体为了同一个目标所进行的一系列实验。例如:搜索团队进行了多次实验测试搜索页上展示什么信息会刺激旅客的订房决策。 - 考虑使用其它的方法来获得更加准确的测量结果。
例如Airbnb就建立了一个全球范围的对照组用以获得更好的评估结果,除了削弱选择偏差之外,还能够解决其它的诸如淡旺季、长期vs.短期等影响因素。同样的,如果有更多的数据,我们还能够把所有入选的方案合并起来进行一次测试,这样就完全不用考虑选择偏差的问题了。但真正这样做的话需要额外的工程作业并且会拖慢产品的发展进程,所以我们也不经常这么做。
最后一点儿思考
在数据驱动决策的过程中,测量扮演者至关重要的角色。因为A/B测试对成本和效率的要求,我们难免要使用同一份数据上进行推断和模型选择。不论是在学术还是在商业世界中关于“p-hacking”之类观念的讨论也都进行很长的时间了。从计量经济学到全基因组关联研究中都有大量的文献试图解决这个问题。通过基于简单假设的选择规则,我们在这里提供的方法能够在不需要过多额外的假设或专业知识的情况下,快速且有效地测量选择偏差,尤其是在规模的在线测试平台中。
在实践过程中,A/B测试的许多特性都使得理论的应用极具挑战性。并不是所有的决策过程都遵循相同的规则。只有在我们同时保持着对统计的热情和对实际环境的认识的时候,我们才能够真正将产品发展的战线继续推进。
更多译文:
诺曼说:请不要再让“临时工”背锅,糟糕的设计才是罪魁祸首
如何避免用户偏见
Facebook设计总监教你释放“声音魔力”
全新的聊天对话交互方式
全部200+篇译文>>
申请加入UXRen翻译组>>

译者:Ivan 审校:Dodo
作者:Milan Shen
原文标题:《Selection Bias in Online Experimentation》
原文链接:https://medium.com/airbnb-engineering/selection-bias-in-online-experimentation-c3d67795cceb
发布日期:May 29, 2017
版权声明:
- 本文版权归:UXRen翻译组 所有;
- 微信公众号转载说明:
1)由于近期微信审理严格,若是该文章未在UXRen公众号上首发,请不要转载;
2)公众号转载时,请在文章底部贴上UXRen公众号二维码。 - 网站转载说明:
1)文章标题必须保留“UXRen译”字样;
2)转载文中必须保留:“UXRen翻译组”、“作者”、“译者”及“审校者”信息;
3)转载文末必须保留本译文网页链接地址; - 如未遵照上述规则转载,视为侵权,UXRen社区保留随时追责的权利。
学习过的统计学知识都还给老师了,-_-||。
晕。。。神神叨叨写了这么多就是一个统计上早就有方法的无偏估计问题。。选择偏差根本不是这么回事好伐。。